
개인정보를 수집하지 않는 검색엔진 duckduckgo 에 대하여
목차
duckduckgo는 좀 특이하다
우리가 PC나 모바일로 “인터넷”에 접속하여 가장 많이 사용하는 것은 무엇일까요? 아마도 “검색”을 가장 많이 사용하지 않나 생각됩니다.
제가 아침에 일어나서 간단한 식사를 하고 컴퓨터 앞에 앉으면 제일 먼저 하는게 “검색” 입니다. 인터넷을 자주 사용하는 분들도 저와 같은 패턴일 가능성이 꽤 높습니다. 그래서 우리는 매일같이 “네이버, 구글” 등의 검색 엔진 혹은 포털사이트를 이용합니다.
국내외에는 여러 검색 엔진 및 포털사이트들이 있습니다. 세계 최대의 검색엔진인 “구글” 을 비롯하여 국내에서 가장 많이 사용하는 검색 엔진인 “네이버”, 카카오에서 운영하는 “다음”, 마이크로소프트의 “빙”, 현재는 이용자수가 많이 줄어들고 몰락했다는 평가를 받지만 여전히 운영중인 “야후” 등이 있습니다.




이들 중에서 국내에서는 구글, 네이버, 다음 등을 유저들이 주로 사용합니다. 최근에는 “구글”이 네이버의 점유율을 턱밑까지 쫒아왔다고 하지요. 그럼에도 국내 검색 환경에서는 여전히 “네이버” 가 높은 점유율을 보유하고 있습니다.
일단 국내에서는 검색 엔진의 점유율이 “네이버”가 높지만 해외로 가면 그렇지 않습니다. 세계 최대의 검색 엔진 “구글”이 절대 우위를 차지하고 있습니다.

구글은 국내에서만 고전을 하지 해외로 나가면 그 막강한 점유율에 놀라게 됩니다. 해외 다른 국가들에서는 평균 90%의 점유율의 검색 엔진 시장을 거의 “독점” 하다 시피 하고 있습니다. 네이버는 전세계로 봤을때 겨우 0.07% 밖에 되지 않습니다.

그런데 여기서 검색 엔진 순위를 보면 눈에 띄는 한 검색 엔진이 있습니다.
위 링크 글에서 보면 전세계 검색 점유율의 0.45 %를 차지하고 있고 6위에 올라있는 검색 엔진인 “duckduckgo” 입니다.

DuckDuckGo 를 알게 된 계기는 “코드도사”를 운영하고 나서 부터 입니다. 사이트를 운영하면 접속자들의 통계가 필요할 때가 있는데 절대다수는 google, 네이버지만 “DuckDuckGo” 에서 유입되는 트래픽이 종종 있어 왔습니다.
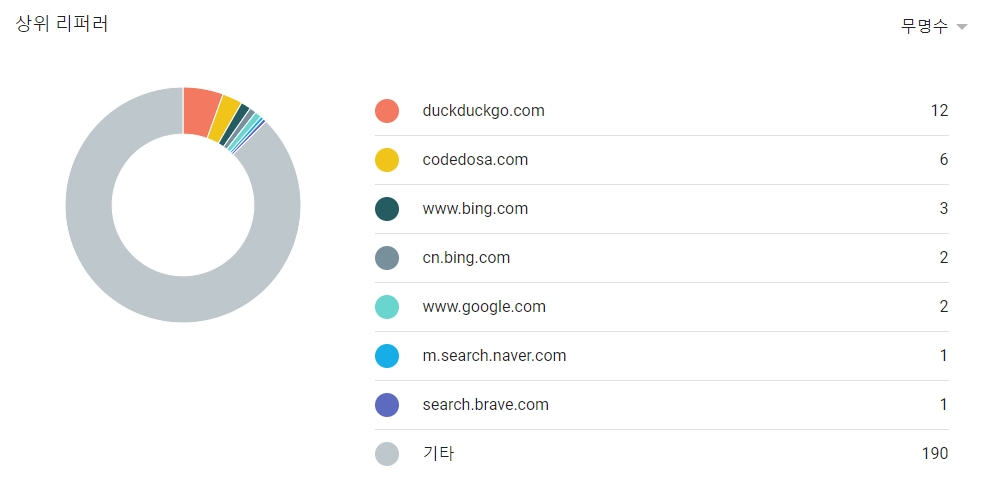
얼마전에 “코드도사 문서” 사이트의 운영을 시작하면서 유입 통계를 보니 꽤 흥미로웠습니다. 영문으로 된 문서들의 트래픽이 “DuckDuckGo” 에서 유입된 트래픽이 가장 많았기 때문이지요. 그래서 DuckDuckGo 를 접속해서 알아보게 되었습니다.
DuckDuckGo 는?
저는 처음에 일반 사이트인줄 알았으나 알고 보니 “검색 엔진” 이었습니다. DuckDuckGo 는 2008년에 처음 개설되었고 미국의 “가브리엘 바인버그(Gabriel Weinberg)” 가 만든 검색 엔진입니다.
특이하게도 DuckDuckGo 는 “오픈소스 검색엔진” 입니다.

DuckDuckGo의 전체 소스가 공개가 된건 아니지만 일부가 github 저장소에 공개가 되어 운영중입니다. 언어도 다양하게 지원하며 “한국어” 도 지원이 되고 있습니다.
DuckDuckGo 는 또한 서버가 “Nginx” 에서 동작을 한다고 하네요. 아무리 점유율이 적다고는 하지만 이용자수가 꽤 많이 때문에 그 트래픽을 “Nginx” 에서 처리한다는게 흥미롭습니다.
DuckDuckGo는 지난 2021년 1월쯤에 개설 후 첫 1억건의 검색 트래픽을 달성했다고 합니다. 물론 다른 유명 검색 엔진에 비해서는 작은 트래픽이지만 뒤늦게 검색 엔진 시장에 뛰어든 후발주자로는 꽤 상징적인 의미입니다. 검색 1억건이 생각보다 쉬운건 아니거든요.
DuckDuckGo 는 무슨 특징을 가지고 있을까?
DuckDuckGo 에 대해서 알아보니 기존의 검색 엔진들과는 약간 다른 특징을 가지고 있었습니다.

개인 정보를 “수집”하지 않는다는 것이 가장 큰 특징입니다.
사실 전세계의 주요 검색엔진들은 알게 모르게 “개인정보”를 수집하고 있습니다. 수집된 개인정보는 접속 브라우저, 사용자의 위치, 검색어, 접속 기기 등등 이런 정보들을 토대로 사용자의 취향에 맞는 광고를 송출하거나 정보들을 추천하는 방식입니다.
이런 개인정보를 수집하는 것은 비단 “검색엔진” 뿐만은 아닙니다. 주요 SNS서비스들도 사용자들의 개인정보를 은근슬쩍 습득을 하며 이런 개인 정보 습득이 최근에는 꽤나 이슈화 되기도 했습니다.

특히 페이스북은 저장되어 있는 “개인정보” 유출되는 사고가 자주 발생(?) 하기도 했습니다. 그래서 페이스북은 한동안 회사 차원에서 위기를 겪기도 했습니다.
이런 검색엔진들과 대형 SNS 서비스 회사들의 “개인정보 습득”은 많은 이들에게 이들 회사들의 서비스가 “부정적인” 인식을 하는데 한몫을 하게 됩니다. 기술의 변화가 빠르고 “개인정보”로도 마음만 먹으면 얼마든지 직/간접적 피해를 볼 수 있는 시대가 되었기 때문이지요.
이런 상황에서 “DuckDuckGo(이하 덕덕고)”의 등장은 사람들에게 서서히 이목을 끌기 시작합니다. 그 이유는 덕덕고의 주요 운영 방침 중에 하나가 “개인정보를 절대 수집하지 않는다” 였기 때문입니다.

이런 운영방침은 “개인정보 취득”에 민감하던 사용자들에게 꽤나 매력적이었던거 같습니다. 덕덕고는 2008년 설립 이후에 서서히 검색엔진 시장에서 점유율을 높이더니 현재는 전세계 검색 엔진 시장에서 무려 6위까지 점유율을 끌어올리는 성과를 거둡니다.(네이버보다 점유율이 높다)
또한 덕덕고는 “오픈소스 프로젝트” 방식으로 검색 엔진이 운영된다는게 꽤나 흥미롭습니다. 그 이유는 사실 구글을 비롯한 주요 검색엔진들의 알고리즘은 철저히 공개되지 않고 있지만 덕덕고의 경우에는 “커뮤니티”를 통해 사용자의 의견을 듣거나 토론을 통해서 그 의견을 반영하는 방식입니다.
또한 개발을 할줄 아는 유저는 직접 덕덕고의 개발에 참여도 가능하다고 합니다. 수정한 코드를 “덕덕고핵”에 올려놓으면 덕덕고 개발자가 검토하여 덕덕고 엔진에 반영하는 방식입니다. 마치 “오픈소스 프로젝트”와 비슷하게 운영이 되는 셈입니다.
“DuckDuckGo” 가 시사하는 점
우연한 기회에 접하게 된 검색 엔진 덕덕고. 그런데 덕덕고를 알게 되면서 참 흥미로운 검색 엔진이라고 생각이 들었습니다.
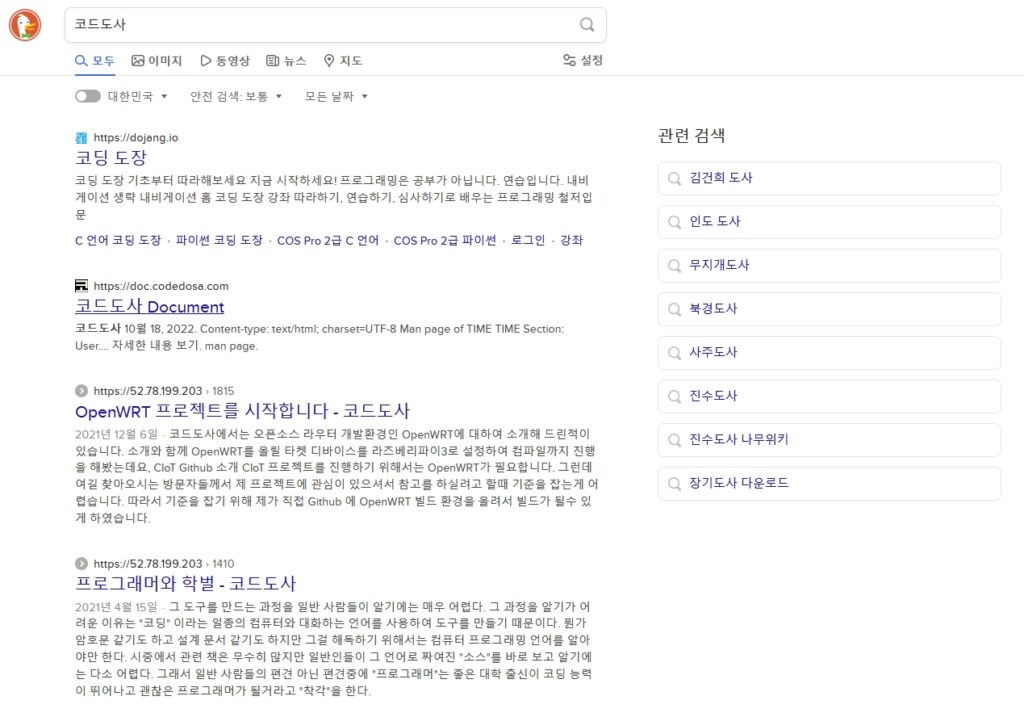
덕덕고에서 “코드도사”로 검색을 한 내용입니다. 검색 결과가 구글이나 네이버만큼 정확한 것은 아니지만 한글로 검색한 결과가 어느정도 코드도사 사이트로 안내를 하는 것을 알 수 있습니다. 한글 검색도 충분히 사용이 가능하군요.
그렇다면 덕덕고는 “수익”을 어떻게 올리는 것일까요? 덕덕고는 회사 규모도 작고 개인정보를 수집하지 않는 only 검색 엔진으로만 회사를 운영하는데 말이지요.

덕덕고의 검색 결과 하단에 보면 위와 같이 수익에 관련된 메시지를 볼 수 있었습니다. 한번 클릭해 봤습니다.

이 문서를 보면 덕덕고가 어떻게 수익을 올리는지에 대한 내용이 설명이 되어 있습니다.
We make money from private ads and affiliate partnerships on our search engine.
우리는 검색 엔진의 비공개 광고 및 제휴 파트너십을 통해 수익을 창출합니다.
덕덕고도 “광고”와 “제휴 파트너쉽”을 통하여 수익을 창출한다고 되어 있군요. 제가 검색을 해보니 검색 결과에 별도로 광고가 붙지는 않던데(보이기에는 말이지요) 검색 결과에 노출된 링크를 광고로 운영하나 봅니다.
또한 좀더 알아보니 “제휴 마케팅” 을 통해 수익을 창출한다고 하니 개인정보를 활용하지 않고도 “검색엔진” 으로 충분히 수익을 창출할 수 있다는게 재밌습니다.
덕덕고의 운영 방식은 마치 “오픈소스” 수익 모델과 비슷하다는 생각이 듭니다.

오픈소스는 내가 개발한 소스를 “전부 공개”를 하지만 공개를 하고 나서 여러 기여자가 조언과 기여를 통해 소스가 계속 발전하고 그 소스를 통해 기술 제휴 등으로 “수수료” 를 얻는 방식으로 수익을 창출하는 방식입니다. 소스가 지속적으로 업데이트가 되면 그만큼 경험과 노하우가 쌓이게 되고 그런게 “기술”이 되어 “돈”을 만들 수 있는 것이지요.
이번에 알게 된 덕덕고의 사례를 보면서 “검색 엔진”도 오픈소스 형태로 발전할 수 있다는 사실을 알게 되었습니다. 그리고 충분히 “수익”이 날 수 있다는 것도 알게 되었습니다.
이런 점은 “오픈소스” 프로젝트를 통해 수익을 창출해 보려는 제게도 많은 것을 시사해 주었습니다. “잘 만든” 오픈소스는 충분한 수익 모델이 되는게 가능하다는 것을 말입니다. 또한 오픈소스 프로젝트의 “검색 엔진” 또한 가능성이 충분하다는 사실을 알게 되었습니다.
향후에 오픈소스 프로젝트를 꼭 진행해 보고 싶은 제게 “한국형 오픈소스 검색엔진”은 꽤나 매력적인 요소가 될수도 있을거 같습니다. 물론 제가 그런 실력이 될지는 미지수이지만 말이지요^^